ElasticSearch–Python接入
之前介绍过文档搜索引擎ElasticSearch(传送门),今天我就来分享一下如何把使用python接入ES,进而作为我们的flask服务器的搜索引擎。
环境搭建与介绍
为了简单起见,本文所用到的ES环境由docker提供。
首先抓取docker镜像。
1
docker pull elasticsearch:6.8.7
运行docker。
1
docker run -d --name es -p 9200:9200 -p 9300:9300 elasticsearch:6.8.7
安装kibana做监控(Optional)
不同环境下安装方式不同。
MacOS:
brew install kibana运行kibana
1
kibana
Python接入
我们先从基本的Python接入开始介绍,主要覆盖一些简单的CURD操作。
安装ES插件包。
1
pip install elasticsearch
引入ES插件包,并创建实例。
1
2from elasticsearch import Elasticsearch
es = Elasticsearch()新增及插入。
主要是使用
index()方法,参数有index(索引名,相当于数据库名)、doc_type(文档类型,相当于表名)、body(内容,相当于一条record)。1
2
3
4
5
6
7body1 = {
'name': 'test hello',
'age': 32,
'school': 'scnu'
}
es.index(index="qii_index", doc_type="table1", body=body1)这里我插入了多条数据用于后面的搜索演示,在Kibana上就能够看到内容。
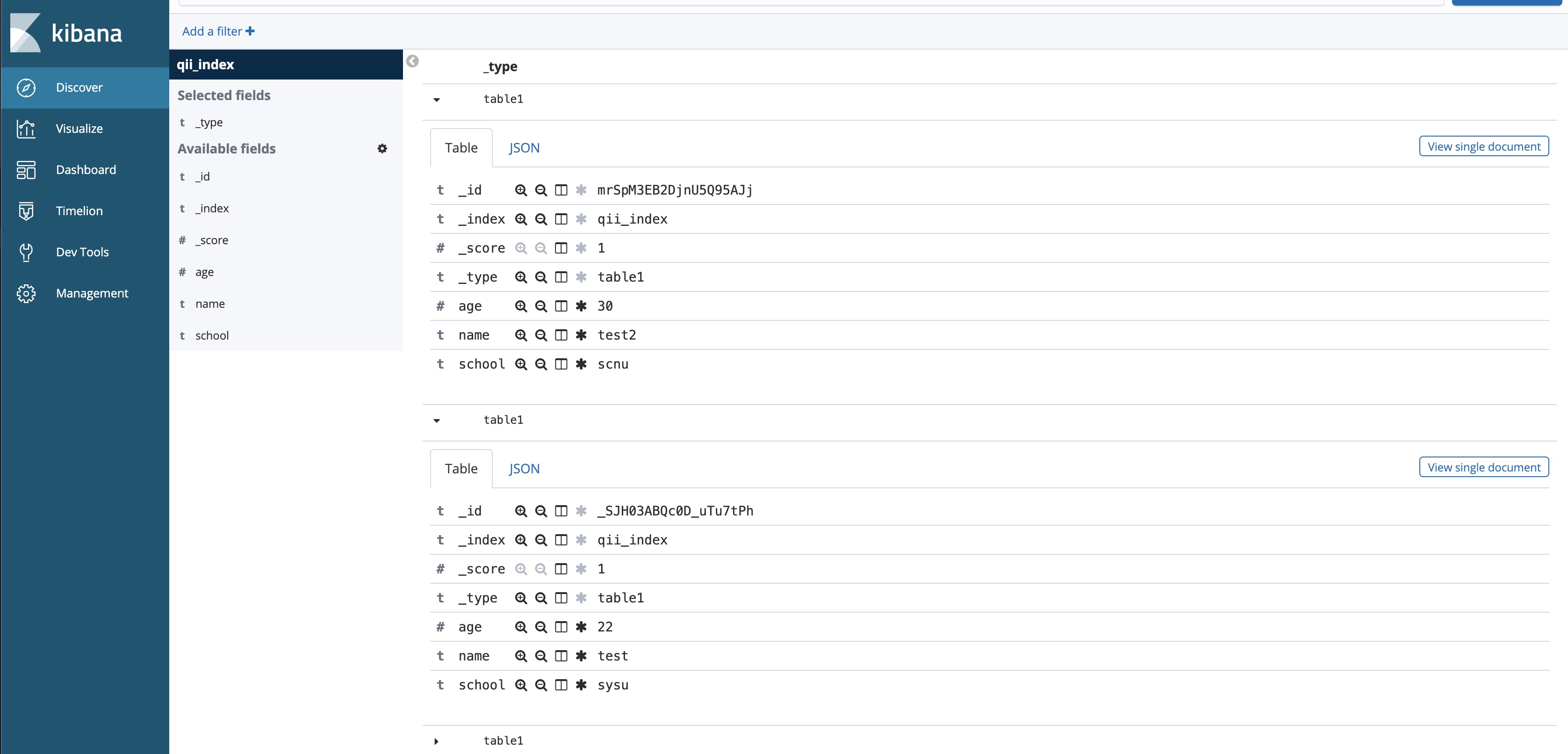
搜索。
主要是使用
search()方法,里面可以搜索参数等。同样地,调用时需要指定index和doc_type。获取所有结果
1
2
3
4result = es.search(index="qii_index", doc_type="table1") // search all result
for item in result["hits"]["hits"]:
print(item["_source"])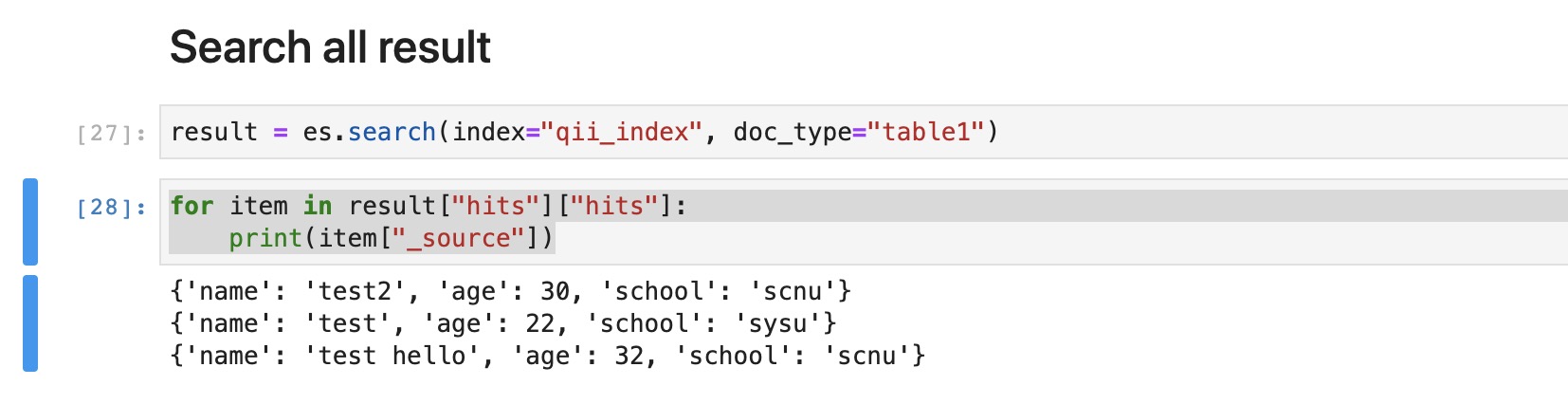
按照名字搜索
1
2
3
4
5
6
7
8
9
10
11
12_query_name_contains = {
'query': {
'match': {
'name': 'test'
}
}
}
result2 = es.search(index="qii_index", doc_type="table1", body=_query_name_contains)
for item in result["hits"]["hits"]:
print(item["_source"])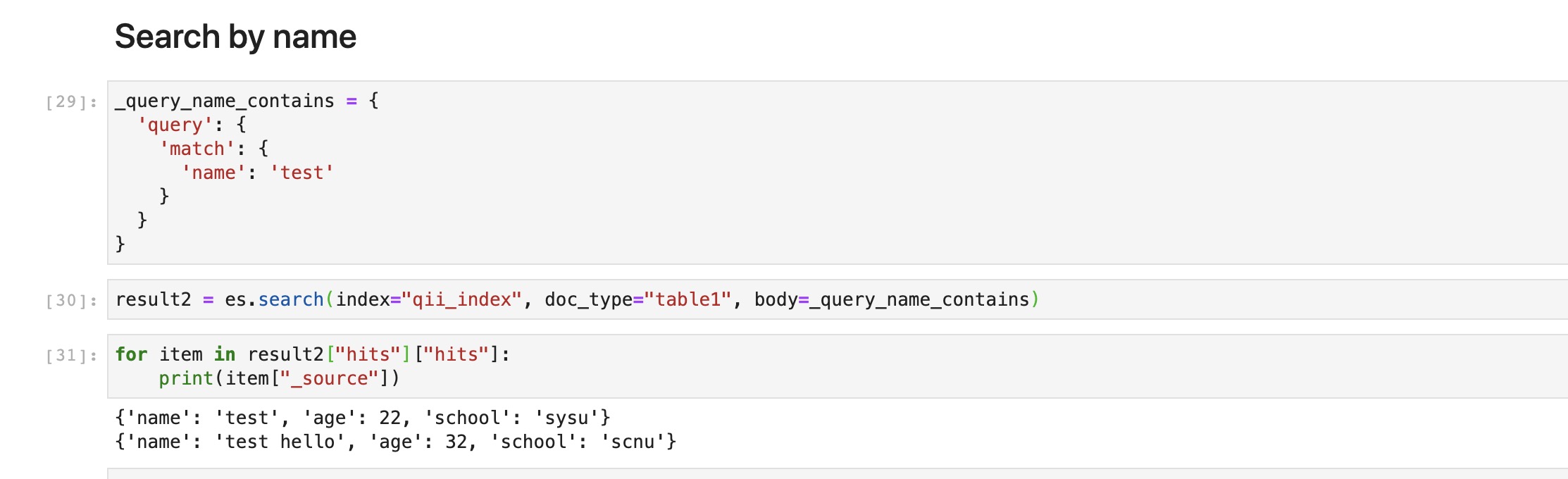
这里的搜索结果可以分析一下,我们搜索的是
test。匹配到的结果是test和test hello,而test2则没有匹配上,说明这个分词器对于英文而言是使用空格切分,匹配是以单词为单位的。我们也可以去验证一下中文的效果。打开Kibana,在Dev Tools中输入以下内容,就能看到分词器是如何去分解一个查询词的。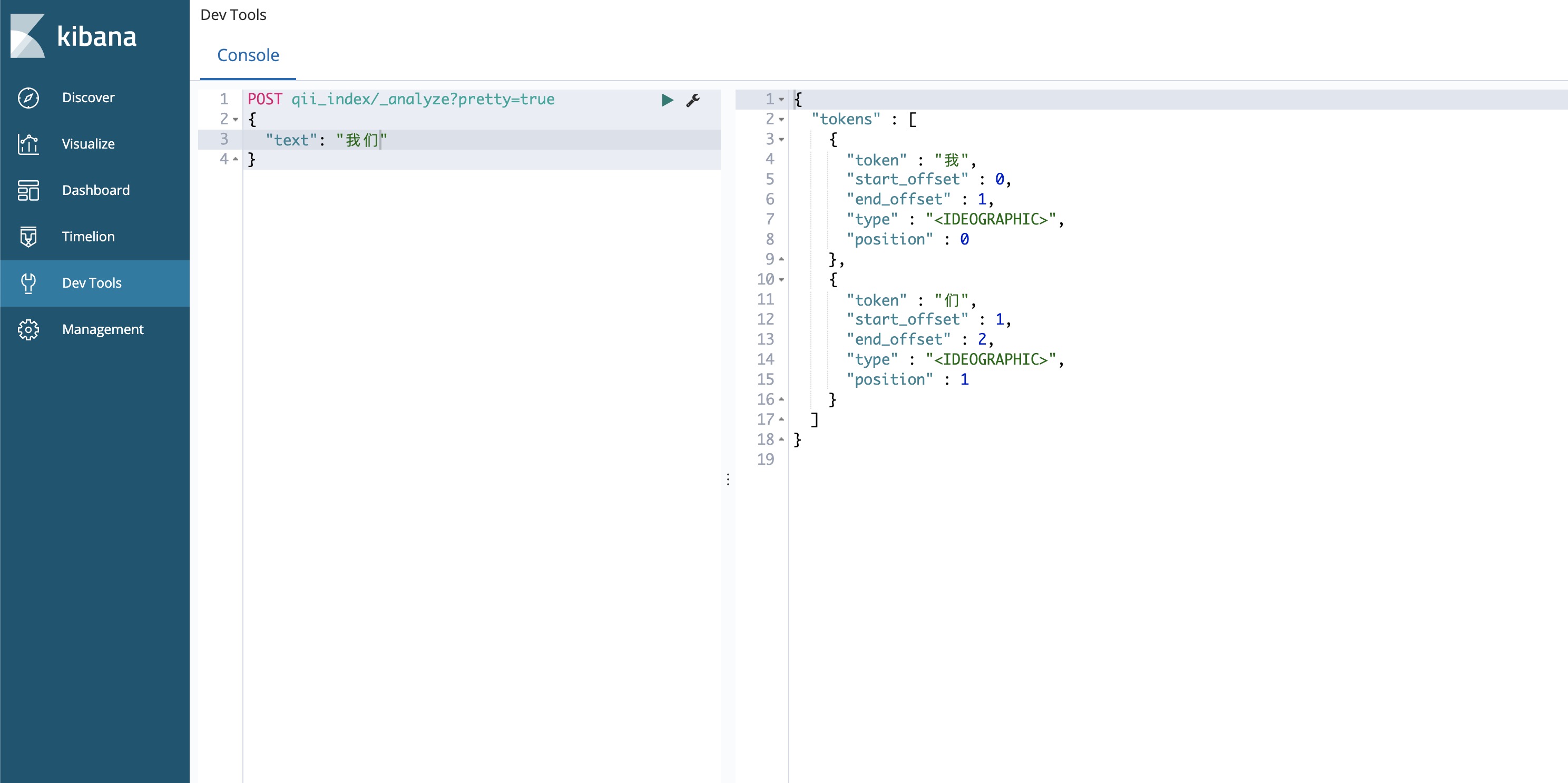
可以看到对于中文来说,是逐个字分开的。关于分词的优化后面会继续讨论。
Flask接入
TBC…

