Introduction
有关网络层的博客发的比较少,最近抽点时间了解一下这块的细节,然后把学习的一些心得分享到这里。在这篇博客主要介绍的是网络层中的负载均衡,这是一块现代软件工程很重要的组成部分。
What is network load balancing?
这部分我们来看看什么是网络负载均衡(Network Load Balancing)。
Network Load Balancing
负载均衡是计算机领域中一个很重要且广泛的概念,并不只是特指网络层。例如,在OS领域中,操作系统通过负载均衡策略去调度各种计算任务,合理分配到不同的CPU;在分布式系统领域中,容器编排调度系统(如k8s)使用负载均衡策略调度不同的实例到不同的计算集群;在网络的领域,网络层通过负载均衡策略调度网络任务到可用的后端服务器。所以负载均衡是一个很广泛的概念,但是在这篇博客,我们把重点放在网络的负载均衡。

上图展示了一个网络中负载均衡最简单的结构。用户发起网络请求,负载均衡器在用户和服务器之间,它有下面几个工作内容:
- 服务发现(Service Discovery):负载均衡器需要知道哪些后端服务器是可用的,需要通过服务发现来得到它们的ip地址;
- 健康检查(Health Checfking):负载均衡器需要通过某种手段去验证后端服务器是否健康,以及能否接受网络请求;
- 负载均衡(Load Balancing):通过某种策略,合理地把用户的请求分配到不同的健康的后端服务器。
使用负载均衡有什么好处呢?
- 命名抽象(Naming Abstraction):对于用户来说,后端服务器的ip地址是抽象的,用户并不需要知道每一个可用的后端服务器地址,它只需要知道负载均衡器的地址即可;
- 容错机制(Fault Tolerance):负载均衡器的服务发现和健康检查使得用户的请求能有效避开不可用的后端服务器,当后端服务器出现部分故障或负载过高的情况,其余的请求仍然能够被正常处理;
- 成本和经济效益(Cost and Performance Benefits):大多数的分布式系统会分布在不同的网络分区,或者一个分布式系统会跨多个网络分区。对于网络分区来说,不同分区之间一般是oversubscribed的,对于同一个分区内,通常是undersubscribed的,负载均衡能够把流量尽可能保持在一个网络分区内,可以提升性能吧,减少网络分区之间的开销。
负载均衡的种类
目前工业界使用最多的就是L4和L7两种负载均衡,这个4层和7层是对应OSI模型而言的。这里的层数,指的是负载均衡过程中,利用到了第几层的信息。如L4意思就是利用到了第四层的信息,即网络层。所以能够利用TCP中的ip和port去做负载均衡。L7的意思就是利用到了第七层的信息,比如对于http请求来说,就可以获得用户的语言、区域甚至cookie信息用于负载均衡。当然,除了这两个之外,还有其他的负载均衡,但是用的不多。
L4 Load Balancing 四层负载均衡

这幅图展示了一个简单的L4负载均衡的工作过程,用户发起一个TCP请求到负载均衡器,负载均衡器替换到网络层的IP地址和port后,重新发起一个新的TCP请求到后端服务器。返回服务器返回信息给负载均衡器,最后负载均衡器再把response返回给用户。这其中用到的最主要的信息就是ip和port,这是第四层中最为关键的信息。
L7 Load balancing 七层负载均衡
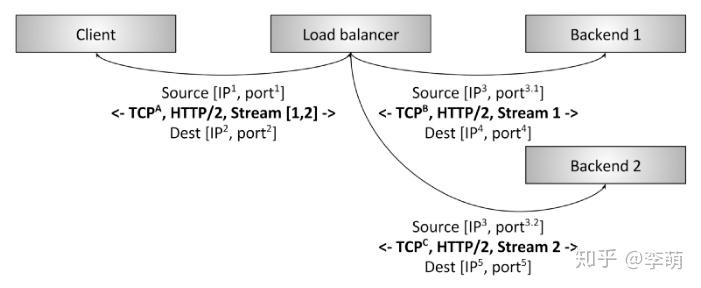
看完L4负载均衡的简单介绍,我觉得这个策略挺合理的,毕竟我们大多数都是用ip+port的形式去定位某一个用户,但是按照用户的维度做负载均衡,这个粒度还是不够细致。原因是当前很多客户端都采用多路复用的模式,即用一条链接发送所有的应用请求(因为创建链接的开销很大,尤其链接需要TLS加密时,开销更大),所以某个用户的请求也应该能够被合理地分配到不同的服务器进行处理。
先来看一个场景,有两个HTTP/2 Client发起通信请求,Client 1每分钟发送1个请求,Client 2每秒20个请求,这两个请求的频率是相差很远的。如果使用L4负载均衡,会按照这两个client的ip+port去负载均衡,Client1的请求分配到A服务器,Client2的请求分配到B服务器,从结果看,B服务器的负载就是A的1200倍了,这好像并没有达到负载均衡的要求。原因是什么呢?仅通过ip+port去分发流量并不够细致,因为4层的信息太少了,这也是为什么要引入7层负载均衡的原因。7层包括了应用层协议,比如http、smtp等,这里面能够利用的信息就多很多了,我们可以根据里面的信息再做更加合理的分发。
所以上面的例子,放到L7负载均衡是这样的。两个请求的内容可能是不一样的,Client1请求的可能是实时性不高的meta信息,而Client2请求的是实时性很高的用户数据,那么可以根据这两个请求实际需要的资源(这个信息在应用层中),去分配到不同的服务器。
Types of Load Balancer Topologies
在这一部分我们来讨论Load Balancer的拓扑类型,所谓拓扑类型指的是负载均衡服务器是怎么部署的。
Middle Proxy 中间代理

这种类型叫中间代理,顾名思义就是负载均衡服务器处于Client和Server的中间。Client通过DNS连接Load Balancer。这种模型是最常用也最通用的模型,部署起来也比较简单,缺点是这里的Load Balancer也是一个故障单点和系统瓶颈。
Edge Proxy 边缘代理

这种类型叫边缘代理,这里的边缘指的是网关的边缘。这种模式可以理解为是中间代理的一个变种,中间代理模式下,Client在公网直接访问到Load Balancer;但是在边缘代理模式下,Load Balancer前面还包含了一个gateway,提供了TLS中断、限速、认证、流量路由等功能。其优缺点和中间代理是一样的,这种模式现在在大厂比较常用。对于一个面向公网的一个大型分布式系统,如果Client直接通过DNS连接Load Balancer是不可控的,也是极其危险的,所以通常会部署一个gateway让所有公网的流量进入系统。
Embedded Client Library 嵌入Client库
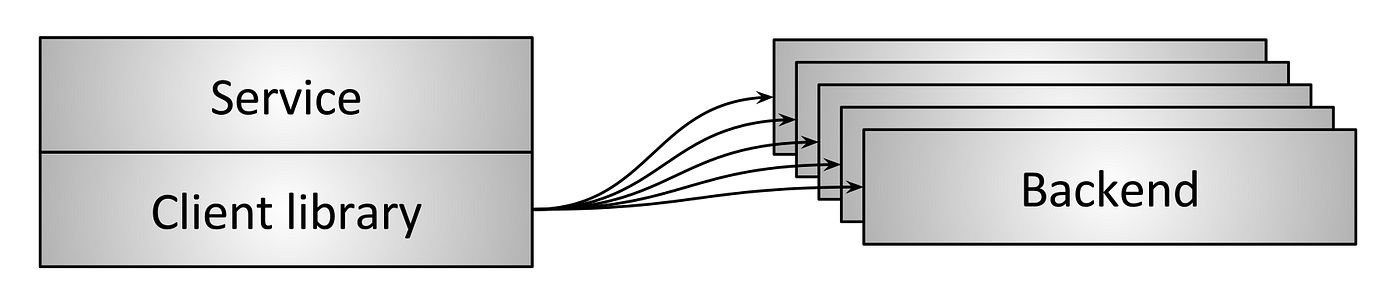
上述两种模型的缺点都是单点故障风险以及不便于横向扩容,为了克服这个问题,有一种解决方法是以库的形式嵌入到服务中。基于库的解决方案带来的好处就是把负载均衡的逻辑都分发到每一个Client中,因此单点故障和瓶颈的问题也就不复存在了。然而这个方法也是有很大限制的。首先是需要使用多种语言去实现负载均衡的逻辑,以适用于不同的Client设备,同时,当这个开发库需要升级时,也需要花费很多资源。
Sidecar Proxy
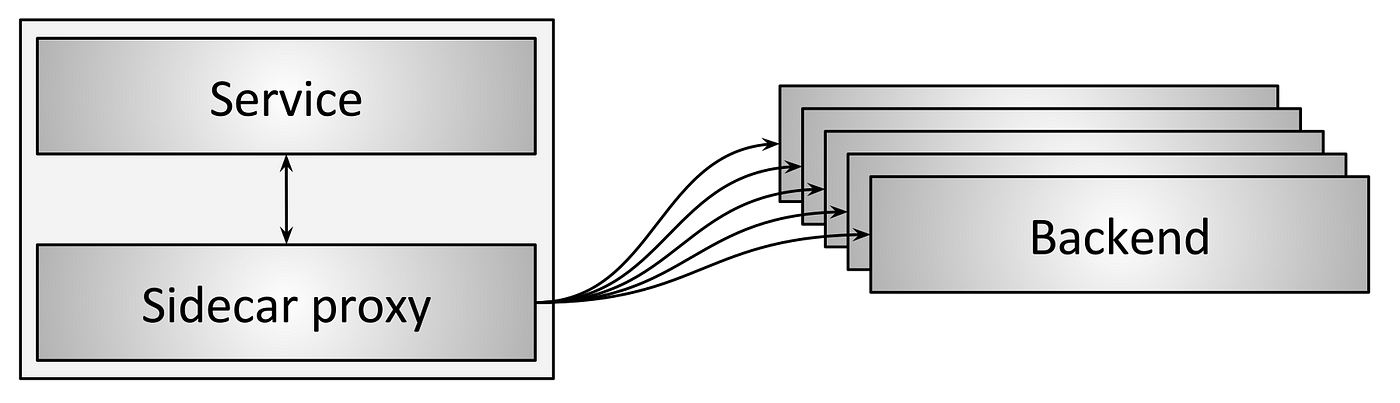
Sidecar proxy是Emdedding Client Libray方案的一个变种,是为了解决库多语言的问题。这个方案通过另外一个不同进程来进行网络访问,通过牺牲一点性能来解决多语言的问题。这种模式是比较新的,但是逐渐变得普遍。

