Intro
这篇博客就向大家介绍一下常用的推荐算法——LFM。LFM(Latent Factor Model),隐语义模型,是一种非常著名的推荐系统算法,它在NetFlix的推荐算法竞赛中获奖,最早被应用于电影推荐中。这里我将会简单介绍其原理,然后实现一个简单的电影推荐系统。
原理
先看看LFM的基本思想:每个用户(user)都有自己对电影(movie)的偏好。我们认为一部电影带有一些latent factor(如动作片、科幻片、爱情片、纪录片等)。所以我们就有以下两条假设:
- 不同的用户对于不同的factor有不同的偏好程度。矩阵P:
|
动作 |
爱情 |
科幻 |
| 用户1 |
0.6 |
0.1 |
0.2 |
| 用户2 |
0.2 |
0.8 |
0.3 |
- 不同的电影含有的factor的比重是不同的。矩阵Q:
|
动作 |
爱情 |
科幻 |
| 电影A |
0.9 |
0.4 |
0.1 |
| 电影B |
0.2 |
0.2 |
0.8 |
根据以上两个矩阵,我们就可以知道用户1对电影A的喜好程度为:
$$
0.6*0.9 + 0.1*0.4+0.2*0.1 = 0.6
$$
对电影B的喜好程度为:
$$
0.6*0.2+0.1*0.2+0.2*0.8 = 0.3
$$
所以我们可以很直观地看出,用户1更喜换电影A。根据这种思路,我们可以计算出每个用户对于每部电影的评分(当然这个评分是我们估计的,直观上看这种估计也是非常合理的)。评分矩阵$\hat{R}$可以这样计算:
$$
\hat{R}=PQ^T
$$
现在估计的问题已经解决,但是LFM最大的问题在于我们如何获得Q和P。在实际应用中,让用户告诉我们对每个类型的偏好系数是不现实的,我们一般获取到的是用户行为,因此我们需要自己构建出一个评分矩阵$R$。我们可以自定义一些规则来将用户行为转变成为评分,如:
- 看完整部电影 = 4
- 分享给别人 = 3
- 收藏 = 2
- 搜索该电影名字 = 1
- 只观看10分钟 = -2
这样我们就可以构建出一个实际的评分矩阵$R$。事实上这是一个非常高维的稀疏矩阵,因为绝大多数的用户都是只看过一小部分的电影。我们可以利用稀疏矩阵这个特性,对$R$作分解。也就是说,我们把构建$R$的问题转化为了用$Q$和$P$两个矩阵的乘积去得到$\hat{R}$。这是一个近似的问题,因此就得到了可优化的代价函数:
$$
J(\theta) = \sum(R_{u,i} - P_{u,k}Q_{k, i})^2
$$
其中$u$是用户,$i$是电影,$k$是laten factor。特别注意,这里的Q与上面的Q是不同的,上面的Q是电影-类别矩阵,这里的是类别-电影矩阵,刚好是转置。
这个就是我们用于优化求解的代价函数。在实际应用中,往往还会在后面加上2范数的罚相$\lambda\parallel P_{u,k} \parallel^2 + \lambda\parallel Q_{k,i} \parallel^2$。最常用的方法就是使用梯度下降法来求解$P$和$Q$。经过学习后,我们就能够得到一个比较理想的$\hat{R}$,然后用这个评分矩阵去估计某一个用户对于某一个电影的感兴趣程度。
梯度下降法推导
我们使用梯度下降法来最优化损失。可以知道,这里我们的参数是P和Q矩阵,所以分别对他们求偏导数。
$$
\frac{\partial J(\theta)}{\partial P_{u,k}} = -2(R_{u,i}-\sum P_{u,k}Q_{k,i})Q_{k,i}+2\lambda p_{u,k} \
\frac{\partial J(\theta)}{\partial Q_{k,i}} = -2(R_{u,i}-\sum P_{u,k}Q_{k,i})P_{u,k}+2\lambda Q_{k,i}
$$
分别更新$P_{u,k}$和$Q_{k, i}$:
$$
P_{u,k}=P_{u,k}+\alpha((R_{u,i}-\sum P_{u,k}Q_{k,i})Q_{k,i} - \lambda P_{u,k}) \
Q_{k,i}=P_{u,k}+\alpha((R_{u,i}-\sum P_{u,k}Q_{k,i})P_{u,k} - \lambda Q_{k,i})
$$
其中上面的系数2合并到了学习率$\alpha$中。$\alpha$一般选取0.01以下的值,而正则化参数$\lambda$则需要根据不同的数据集来调试。
实战
下面我将实现一个简单的电影推荐系统。首先获取数据集:传送门。在recommended for education and development中下载Small数据集。

下载并解压后其实我们可以看到,里面包含了几个csv数据,我们主要用到两个数据ratings.csv(用户对自己看过的电影的评分)和movies.csv(电影信息)。
注意:这里的数据是定期更新的,并且官方不会保留历史版本,因此大家实战的时候可能与我的结果不一样。
数据预处理
首先对原始数据进行预处理,主要是将csv读入,然后提取表格中有用的信息。这里有两个特别要注意的:
- 我们使用索引号(index)来替代
movieId。这是因为movieId很大,构建出来的矩阵会很大,使用索引号替代movieId能提高效率。这一步要做的就是在movies表中建立movieId与index的对应关系,然后将这个表格合并到ratings表中(根据相同的movieId)。
- 及时保存处理后的数据。这是在数据处理中一个很好的习惯,因为数据处理需要耗费大量的时间,所以一旦处理后我们应该保存起来。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
ratings_df = pd.read_csv('ml-latest-small/ratings.csv')
ratings_df.tail()
movies_df = pd.read_csv('ml-latest-small/movies.csv')
movies_df.tail()
movies_df['movieRow'] = movies_df.index
movies_df.tail()
movies_df = movies_df[['movieRow', 'movieId', 'title']]
movies_df.to_csv('moviesProcessed.csv', index=False, header=True, encoding='utf-8')
movies_df.tail()
ratings_df = pd.merge(ratings_df, movies_df, on='movieId')
ratings_df.head()
ratings_df = ratings_df[['userId', 'movieRow', 'rating']]
ratings_df.to_csv('ratingProcessed.csv', index=False, header=True, encoding='utf-8')
ratings_df.head()
|
创建rating矩阵和record矩阵
我们先来看看这两个矩阵是什么。
- rating矩阵就是我们之前提到的$R$评分矩阵,它是用户对电影的真实评分,是基于用户数据我们计算出来的。
- record矩阵是记录用户评分记录的矩阵。如果用户$i$与电影$j$有评分记录,那么$record(i,j) = 1$。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
userNo = ratings_df['userId'].max() + 1
movieNo = ratings_df['movieRow'].max() + 1
userNo
movieNo
rating = np.zeros((movieNo, userNo))
flag = 0
ratings_df_length = np.shape(ratings_df)[0]
for index, row in ratings_df.iterrows():
rating[int(row['movieRow']), int(row['userId'])] = row['rating']
flag += 1
print('processed %d, %d left' % (flag, ratings_df_length - flag))
record = rating > 0
record
record = np.array(record, dtype=int)
record
|
构建学习模型
首先是对数据进行一个标准化处理。这是数据处理经常用的一个步骤,它可以提高数据处理的速度和精度。一般来说可以用sklearn来实现,但这里比较简单,不妨自己写一下。核心的思路就是:原来的评分-平均评分=标准化后评分。这样处理后每个评分都集中在一个区间中。
然后就使用tensorflow构建学习模型。我们随机初始化$Q$和$P$两个矩阵(使用正态分布)。然后定义好损失函数、优化器等。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
def normalizeRatings(rating, record):
m, n = rating.shape
rating_mean = np.zeros((m, 1))
rating_norm = np.zeros((m, n))
for i in range(m):
idx = record[i, :] != 0
rating_mean[i] = np.mean(rating[i, idx])
rating_norm[i, idx] -= rating_mean[i]
return rating_norm, rating_mean
rating_norm, rating_mean = normalizeRatings(rating, record)
rating_norm = np.nan_to_num(rating_norm)
rating_norm
rating_mean = np.nan_to_num(rating_mean)
rating_mean
num_features = 10
X_parameter = tf.Variable(tf.random_normal([movieNo, num_features], stddev=0.35))
Theta_parameter = tf.Variable(tf.random_normal([userNo, num_features], stddev=0.35))
loss = 1/2 * tf.reduce_sum(((tf.matmul(X_parameter, Theta_parameter, transpose_b=True) - rating_norm)*record)**2) + 1/2 * (tf.reduce_sum(X_parameter**2) + tf.reduce_sum(Theta_parameter**2))
optimizer = tf.train.AdamOptimizer(1e-4)
train = optimizer.minimize(loss)
|
训练模型
训练模型的部分主要是tensorflow的操作,这里就不仔细讲解了。我们可以使用tensorboard可视化工具来看到训练过程。
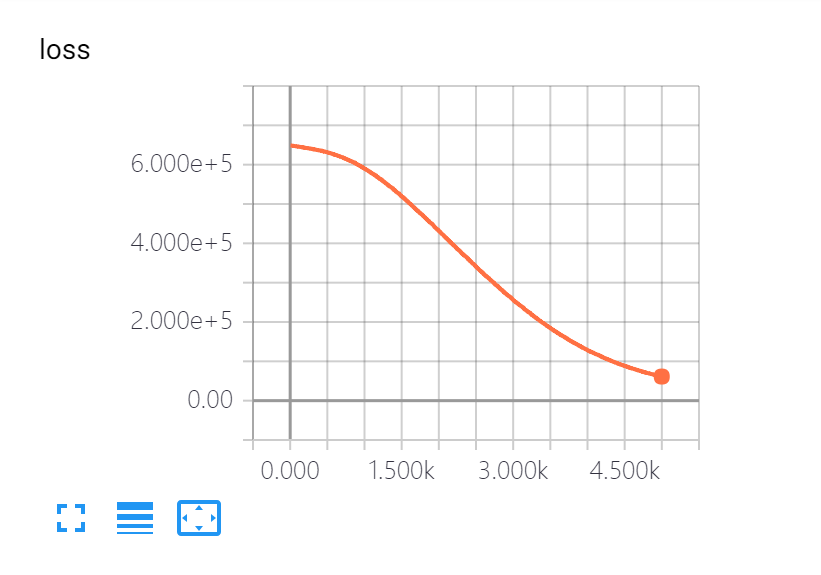
可以看出损失函数随着训练次数的增加在下降。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
tf.summary.scalar('loss', loss)
summaryMerged = tf.summary.merge_all()
filename = './movie_tensorboard'
writer = tf.summary.FileWriter(filename)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(5000):
_, movie_summary = sess.run([train, summaryMerged])
writer.add_summary(movie_summary, i)
|
评估模型
从训练结果中获取到用于预测的模型(实质上就是一个预测的评分矩阵$\hat{R}$,$\hat{R}=QP^T$)。同时我们可以输出一下误差。
Code:
1
2
3
4
5
6
7
8
|
Current_X_parameters, Current_Theta_parameters = sess.run([X_parameter, Theta_parameter])
predicts = np.dot(Current_X_parameters, Current_Theta_parameters.T) + rating_mean
errors = np.sqrt(np.sum((predicts - rating)**2))
errors
|
测试
添加用户输入提示,获取一个用户Id,在$\hat{R}$中将该列提取出来并且排序,将评分排名前20的电影信息输出。
Code:
1
2
3
4
5
6
7
8
9
10
11
12
|
user_id = input('您要向哪位用户进行推荐?请输入用户编号:')
sortedResult = predicts[:, int(user_id)].argsort()[::-1]
idx = 0
print('为该用户推荐的评分最高的20部电影是:'.center(80, '='))
for i in sortedResult:
print('评分:%.2f,电影名:%s' % (predicts[i, int(user_id)], movies_df.iloc[i]['title']))
idx += 1
if idx == 20: break
|
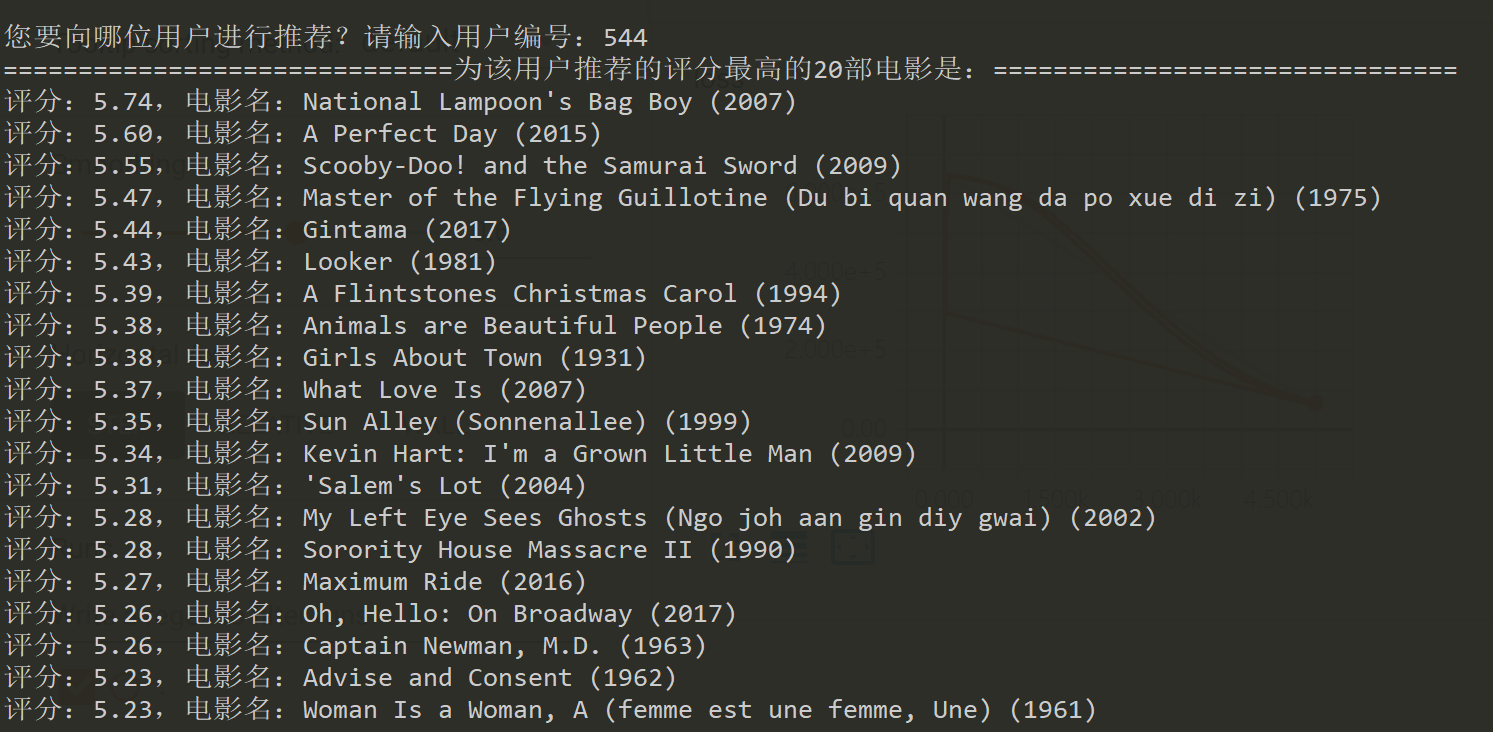
这样,我们就成功构建起一个简单的电影推荐系统了。
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
|
import pandas as pd
import numpy as np
import tensorflow as tf
ratings_df = pd.read_csv('ml-latest-small/ratings.csv')
ratings_df.tail()
movies_df = pd.read_csv('ml-latest-small/movies.csv')
movies_df.tail()
movies_df['movieRow'] = movies_df.index
movies_df.tail()
movies_df = movies_df[['movieRow', 'movieId', 'title']]
movies_df.to_csv('moviesProcessed.csv', index=False, header=True, encoding='utf-8')
movies_df.tail()
ratings_df = pd.merge(ratings_df, movies_df, on='movieId')
ratings_df.head()
ratings_df = ratings_df[['userId', 'movieRow', 'rating']]
ratings_df.to_csv('ratingProcessed.csv', index=False, header=True, encoding='utf-8')
ratings_df.head()
userNo = ratings_df['userId'].max() + 1
movieNo = ratings_df['movieRow'].max() + 1
userNo
movieNo
rating = np.zeros((movieNo, userNo))
flag = 0
ratings_df_length = np.shape(ratings_df)[0]
for index, row in ratings_df.iterrows():
rating[int(row['movieRow']), int(row['userId'])] = row['rating']
flag += 1
print('processed %d, %d left' % (flag, ratings_df_length - flag))
record = rating > 0
record
record = np.array(record, dtype=int)
record
def normalizeRatings(rating, record):
m, n = rating.shape
rating_mean = np.zeros((m, 1))
rating_norm = np.zeros((m, n))
for i in range(m):
idx = record[i, :] != 0
rating_mean[i] = np.mean(rating[i, idx])
rating_norm[i, idx] -= rating_mean[i]
return rating_norm, rating_mean
rating_norm, rating_mean = normalizeRatings(rating, record)
rating_norm = np.nan_to_num(rating_norm)
rating_norm
rating_mean = np.nan_to_num(rating_mean)
rating_mean
num_features = 10
X_parameter = tf.Variable(tf.random_normal([movieNo, num_features], stddev=0.35))
Theta_parameter = tf.Variable(tf.random_normal([userNo, num_features], stddev=0.35))
loss = 1/2 * tf.reduce_sum(((tf.matmul(X_parameter, Theta_parameter, transpose_b=True) - rating_norm)*record)**2) + 1/2 * (tf.reduce_sum(X_parameter**2) + tf.reduce_sum(Theta_parameter**2))
optimizer = tf.train.AdamOptimizer(1e-4)
train = optimizer.minimize(loss)
tf.summary.scalar('loss', loss)
summaryMerged = tf.summary.merge_all()
filename = './movie_tensorboard'
writer = tf.summary.FileWriter(filename)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(5000):
_, movie_summary = sess.run([train, summaryMerged])
writer.add_summary(movie_summary, i)
Current_X_parameters, Current_Theta_parameters = sess.run([X_parameter, Theta_parameter])
predicts = np.dot(Current_X_parameters, Current_Theta_parameters.T) + rating_mean
errors = np.sqrt(np.sum((predicts - rating)**2))
errors
user_id = input('您要向哪位用户进行推荐?请输入用户编号:')
sortedResult = predicts[:, int(user_id)].argsort()[::-1]
idx = 0
print('为该用户推荐的评分最高的20部电影是:'.center(80, '='))
for i in sortedResult:
print('评分:%.2f,电影名:%s' % (predicts[i, int(user_id)], movies_df.iloc[i]['title']))
idx += 1
if idx == 20: break
|
总结
这里通过构建一个简单的电影推荐系统来帮助理解LFM。其实质是矩阵的UV分解和机器学习优化参数。谢谢!

