前言
fork()函数是在Linux操作系统中创建进程的函数,在多进程编程中非常重要,在这篇post我就来给大家介绍一下fork的用法以及一些注意事项。
fork过程
基本过程为:在父进程中调用fork(),系统会创建一个子进程。在父进程中,fork()返回子进程的进程号(pid);在子进程中,fork()返回的是0;如果创建失败,返回-1。
fork()的用法本身并不复杂,让我们从下面这段代码入手分析。
1 |
|
运行这段代码,结果如下: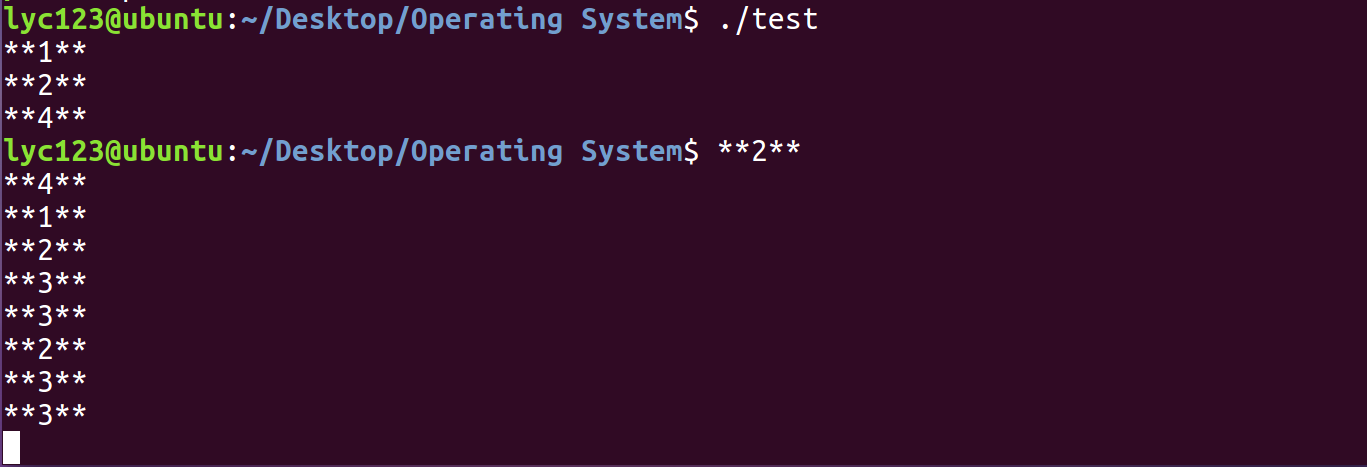
根据上面所说的过程,我们使用流程图分析得到: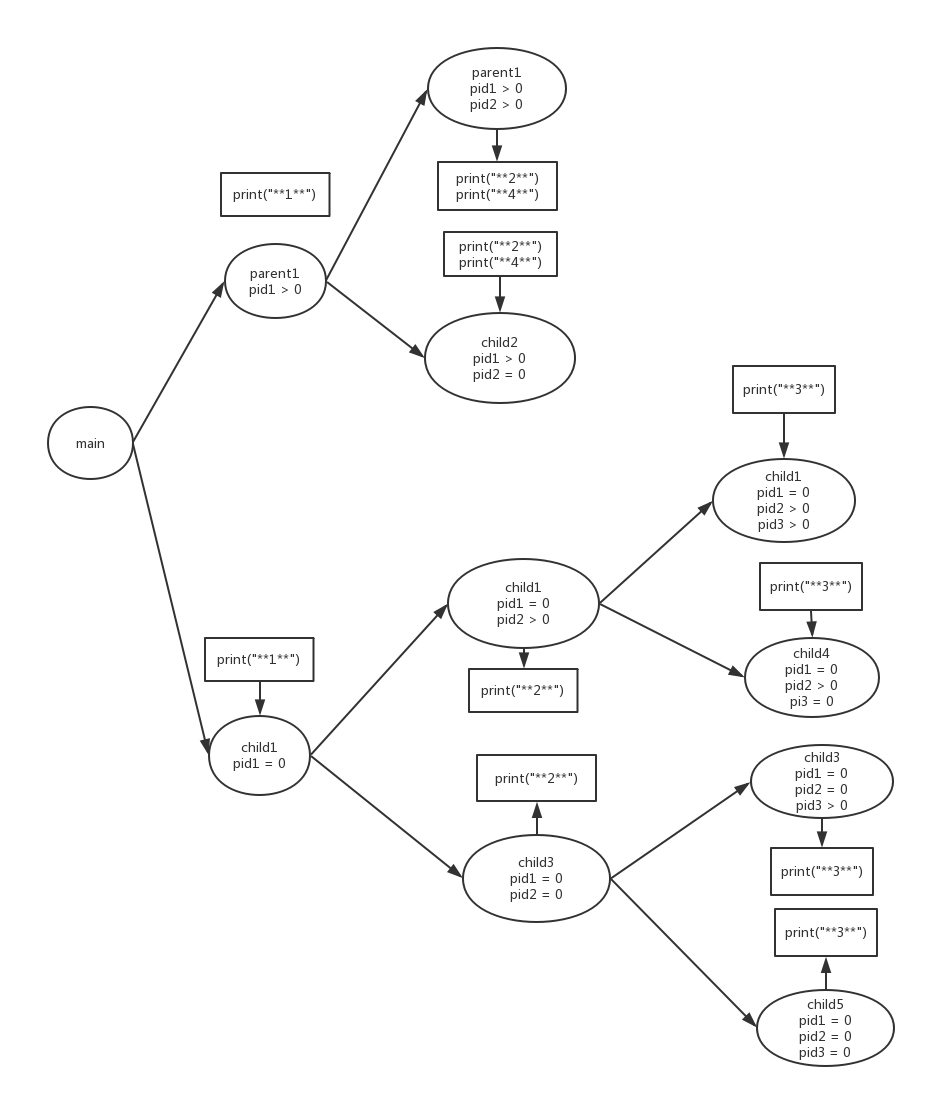
需要注意的是,我们只能够确定每个进程完成的任务,而不能确定他们之间执行的顺序,在不同机器上,它们的执行顺序可能会不同,这取决于系统的调度算法。
小结
经过这个实验,对fork()调用有如下总结:
- (1)子进程复制父进程的变量、内存与缓冲区,但是它们的数据空间是相互独立的,即父子进程之间不共享这些数据空间。
- (2)父子进程对打开文件是共享的。
fork()调用后,子进程会继承父进程所打开的文件表,该文件表是由内核维护的,父子进程共享文件状态、偏移量等。也就是说,当父进程关闭文件时,子进程的文件描述符仍然有效,相应的文件表也不会被释放。 - (3)为了提高效率,
fork()调用并不用立即复制所有的数据空间。这里采用了COW(Copy-On-Write)策略,即当父子进程任何一个需要修改数据段、堆、栈的时候,才把相应的数据复制(仅复制修改的区域)。 - (4)父子进程唯一共享的存储空间只有代码段(只读),且是
fork()后的代码段。子进程和父进程继续执行fork()调用之后的命令。
关于fork()的一些基本知识就分享到这里了,谢谢!

